데이터 하우스 가이드

 Introduction
Introduction
디파이너리 Data House는 고객사가 이미 수집 혹은 보유한 데이터를 디파이너리 콘솔에 업로드하여 디파이너리 SDK로 수집한 데이터와 고객사 데이터를 결합할 수 있는 기능입니다. 이를 통해 고객사의 데이터를 디파이너리 콘솔에서 제어하고 리포트로 확인할 수 있습니다.
Data 종류
Data House에 업로드할 수 있는 데이터는 크게 두 가지입니다.
Event Log Table
이벤트 로그 데이터는 고객사 내부 DB에서 추출한 시계열 데이터를 기반으로 구성된 테이블입니다. 이 데이터를 CDP 서비스에서 통합하여 시간적 흐름에 따라 체계적으로 관리하며, 분석, 시각화, 개인화 등 다양한 목적으로 활용됩니다.
Example
- 고객사 앱에서 실행한 이벤트로그
- 고객사 앱에서 자체적으로 수집했거나 타사에서 수집한 어트리뷰션 로그
Meta Table
메타 데이터는 고객사 내부 DB에서 추출한 고유한 ID, 이름, 소유자 등의 정보를 담고 있는 테이블입니다. 이 테이블은 데이터의 식별을 위한 주요 정보를 관리하고, 데이터의 품질과 정확성을 유지하기 위해 사용됩니다. 이렇게 구성된 메타 데이터는 이벤트 로그 데이터와 결합하여 활용되며, CDP 서비스에서 다양한 비즈니스 목적으로 효과적으로 활용됩니다.
Example
- 사용자 ID를 기준으로 나이 / 성별 / 주소 / VIP 여부 등의 정보가 들어간 테이블
Event Log Table 생성
1. 기본 설정
데이터 테이블의 이름, 간단한 설명을 입력하고 타입을 설정합니다. 데이터 저장유형은 "이벤트 로그 데이터"로 설정해야 합니다.
2. 이벤트 로그 데이터 주요 키 설정
Event Log Table에서 업로드할 때 사용할 데이터 주요 키를 설정합니다.
Time Key
이벤트 로그 데이터의 시간 항목을 설정합니다.
※ 필수 키이며, null 값은 허용되지 않습니다.
| 구분 | 정의 |
|
Key Name |
Time Key의 이름을 설정합니다. |
| Type |
데이터의 타입을 설정합니다. |
| Display Name | 디파이너리 콘솔에서 보여질 이름을 설정합니다. |
| Description | 키에 대한 설명을 입력합니다. |
Deduplication Key
데이터의 유효성을 검증하는 키를 설정합니다. 해당 키의 데이터를 기반으로 중복된 아이템을 제거합니다. 예를 들어, 과거에 추가된 Row 수정하면 Deduplication Key를 기준으로 변경시 동일한 일자(UTC 기준)의 데이터만 업데이트 됩니다.
※ 필수 키이며, null 값은 허용 되지 않습니다.
| 구분 | 정의 |
|
Key Name |
Deduplication Key의 이름을 설정합니다. |
| Type |
데이터의 타입을 설정합니다. |
| Display Name | 디파이너리 콘솔에서 보여질 이름을 설정합니다. |
| Description | 키에 대한 설명을 입력합니다. |
3. 데이터 설계
설정된 Time Key / Deduplication Key를 기준으로 업로드할 데이터 컬럼을 설정합니다. 컬럼은 아이템 유형에 따라 고정형 / 반고정형으로 구분하며 최대 1,000개 까지 세팅할 수 있습니다.
아이템 유형
아이템 유형을 기준으로 데이터 저장 여부를 설정합니다.
- 고정형
컬럼 추가 시 설정한 데이터 형태의 데이터만 저장합니다. - 반고정형
특정 이름으로 시작하는 데이터 명 및 데이터 타입이 매칭되면 데이터를 저장합니다.- Prefix 규칙
컬럼명 prefix:데이터 타입 - 예시) 컬럼명 category_string으로 설정되어있을 경우
- 결과) 컬럼명이 category_1:string / category_2:string / category_3:string 등으로 들어오는 데이터 모두 저장
- Prefix 규칙
컬럼 추가
추가될 컬럼의 데이터를 설정합니다.
| 구분 | 정의 |
|
Key Name |
데이터 컬럼의 키 이름을 설정합니다. |
|
식별자 설정(옵션) |
생성하는 컬럼을 식별자로 설정하여 오디언스 세그먼트로 활용할 수 있습니다. |
| Type |
데이터의 타입을 설정합니다. 컬럼 데이터 타입은 다음의 5개 타입을 지원합니다. |
| Display Name | 디파이너리 콘솔에서 보여질 이름을 설정합니다. |
| Description | 키에 대한 설명을 입력합니다. |
| 필수값 설정 여부 | 해당 값의 필수값 여부를 설정합니다. |
Meta Table 생성
1. 기본 설정
데이터 테이블의 이름, 간단한 설명을 입력하고 타입을 설정합니다. 데이터 저장유형은 "메타 데이터"로 설정해야 합니다.
2. 메타 데이터 주요 키 설정
Meta Table에서 업로드할 때 사용할 데이터 주요 키를 설정합니다.
Unique Key
Meta Table에서 데이터 업로드할 때 메인이 되는 키를 설정합니다. 이 키에 해당하는 데이터를 기반으로 중복되는 데이터를 제거합니다.
※ 필수 키이며, null 값은 허용 되지 않습니다.
| 구분 | 정의 |
|
Key Name |
Unique Key의 키 이름을 설정합니다. |
| 식별자 설정(옵션) |
생성하는 컬럼을 식별자로 설정하여 오디언스 세그먼트로 활용할 수 있습니다. |
| Type |
데이터의 타입을 설정합니다. |
| Display Name | 디파이너리 콘솔에서 보여질 이름을 설정합니다. |
| Description | 키에 대한 설명을 입력합니다. |
Version Key
동일한 Unique Key 값이 들어올 경우 Version Key 값이 큰 기준으로 업데이트됩니다.
※ 필수 키이며, null 값은 허용 되지 않습니다.
| 구분 | 정의 |
|
Key Name |
해당 데이터 컬럼의 키 이름을 설정합니다. |
| Type |
데이터의 타입을 설정합니다. |
| Display Name | 디파이너리 콘솔에서 보여질 이름을 설정합니다. |
| Description | 키에 대한 설명을 입력합니다. |
3. 데이터 설계
설정된 Unique Key / Version Key를 기준으로 업로드할 데이터의 컬럼을 설정합니다. 컬럼은 최대 1,000개까지 세팅할 수 있습니다.
컬럼 추가
추가될 컬럼의 데이터를 설정합니다.
| 구분 | 정의 |
|
Key Name |
데이터 컬럼의 키 이름을 설정합니다. |
|
식별자 설정(옵션) |
생성하는 컬럼을 식별자로 설정하여 오디언스 세그먼트로 활용할 수 있습니다. |
| Type |
데이터의 타입을 설정합니다. 컬럼 데이터 타입은 다음의 5개 타입을 지원합니다. |
| Display Name | 디파이너리 콘솔에서 보여질 이름을 설정합니다. |
| Description | 키에 대한 설명을 입력합니다. |
| 필수값 설정 여부 | 해당 값의 필수값 여부를 설정합니다. |
Data Pipeline
데이터 테이블 설정이 완료되면 해당 테이블의 데이터를 업로드합니다.
데이터 업로드는 크게 두 가지 방법을 지원합니다.
데이터 업로드
SFTP
Filezilla 와 같은 파일 전송 클라이언트를 이용하여 데이터를 업로드합니다. csv 파일만을 지원하며 파일 업로드시 반드시 디파이너리 콘솔에서 지정한 폴더명으로 폴더를 생성하고 해당 폴더에 데이터 파일을 업로드 합니다.
File upload
직접 파일을 업로드 합니다. csv 파일만 지원합니다.
데이터 처리
에러메시지 종류
| 에러 메시지 | 설명 | 해결책 |
| No Data | 빈 파일 | 빈 파일입니다. 파일의 내용을 확인해주세요. |
| File {파일명} is not found or duplicated. | 파일을 찾을 수 없음 | 파일을 다시 올려주세요. |
| Required Field Missing: {string.join(”,”, 누락된 주요키)} |
헤더 주요키 누락 | CSV 헤더에 주요키 값을 채우세요. |
| CSV Error : Row is too long - Record(line {라인 넘버}) : {해당 행의 내용 1,000글자} |
행 길이 제한 초과 | 행의 글자수를 1천만자 미만으로 입력하세요.(올바른 CSV포맷인지 확인하세요.) 해당 Line을 수정하세요. |
| CSV Error : Failed to validate schema( primary key [{누락된 주요키}] is required) |
행 주요키 누락 | CSV 행에 주요키 값을 채우세요. |
| CSV Error : The num of fields is less than the number of header's fields, Record(line {라인 넘버}) : {해당 행의 내용} |
헤더의 컬럼 수보다 행의 컬럼 수가 적음 |
CSV 헤더와 행의 컬럼 수가 일치하지 않습니다. 해당 Line을 수정하세요. |
| CSV Error : Empty required field(Col : {누락된 컬럼명}, Expected Type : {데이터 타입}, Format : {날짜 형식일 경우 포맷}) - Record(line {라인 넘버}) : {해당 행의 내용} |
필수 컬럼 값 누락 | 필수 컬럼 값이 누락되어 있습니다. 해당 Line을 수정하세요. |
| CSV Error : Failed to parse(Col : {누락된 컬럼명}, Expected Type : {데이터 타입}, Format : {날짜 형식일 경우 포맷}, Actual Value: {실제 행에 포함된 값}) - Record(line {라인 넘버}) : {해당 행의 내용} |
데이터 파싱 에러 | 데이터형이 일치하지 않습니다. 해당 Line을 수정하세요. |
| CSV Error : {etc}CSV Error : {예외 메시지} - Record(line {라인 넘버}) : {해당 행의 내용} |
기타 CSV 파싱 실패 | 기타사항으로 발생한 문제입니다. 해당 Line을 수정하세요. |
특이 케이스
1. 특정 행의 헤더 컬럼 수를 초과하는 경우
이름,나이
John,30,남성
위 예시에서 남성 데이터는 헤더 컬럼 수를 초과하므로 무시됩니다.
2. 쌍따옴표 이스케이프( 큰따옴표내에서, 큰따옴표 두 개 연속 사용)
이름,메모
John,"He said, ""I am happy."""
큰따옴표(")내에서 큰따옴표를 표현하려면 두 개의 연속된 큰따옴표("")를 사용해야 합니다.
처리 불가
1. 쌍이 맞지 않는 큰따옴표(") 포함하는 경우(개행 여부 관계 없음)
이름,메모
John,"He said, "I am happy."
위 예시에서 메모 필드의 큰따옴표가 쌍이 맞지 않으므로, 이러한 형식은 처리할 수 없습니다.
2. 쌍따옴표 이스케이프가 큰따옴표(")로 감싸지지 않은 경우
이름,메모
John,"He said, ""I am happy.""
큰따옴표(")로 이스케이프된 텍스트는 반드시 전체 필드가 큰따옴표로 둘러싸여야 합니다.
3. 쌍따옴표 역슬래시 이스케이프
이름,메모
John,"He said, ∖"I am happy.∖""
CSV에서는 역슬래시(∖)로 이스케이프를 지원하지 않습니다. 따라서 이 형태는 처리할 수 없습니다.
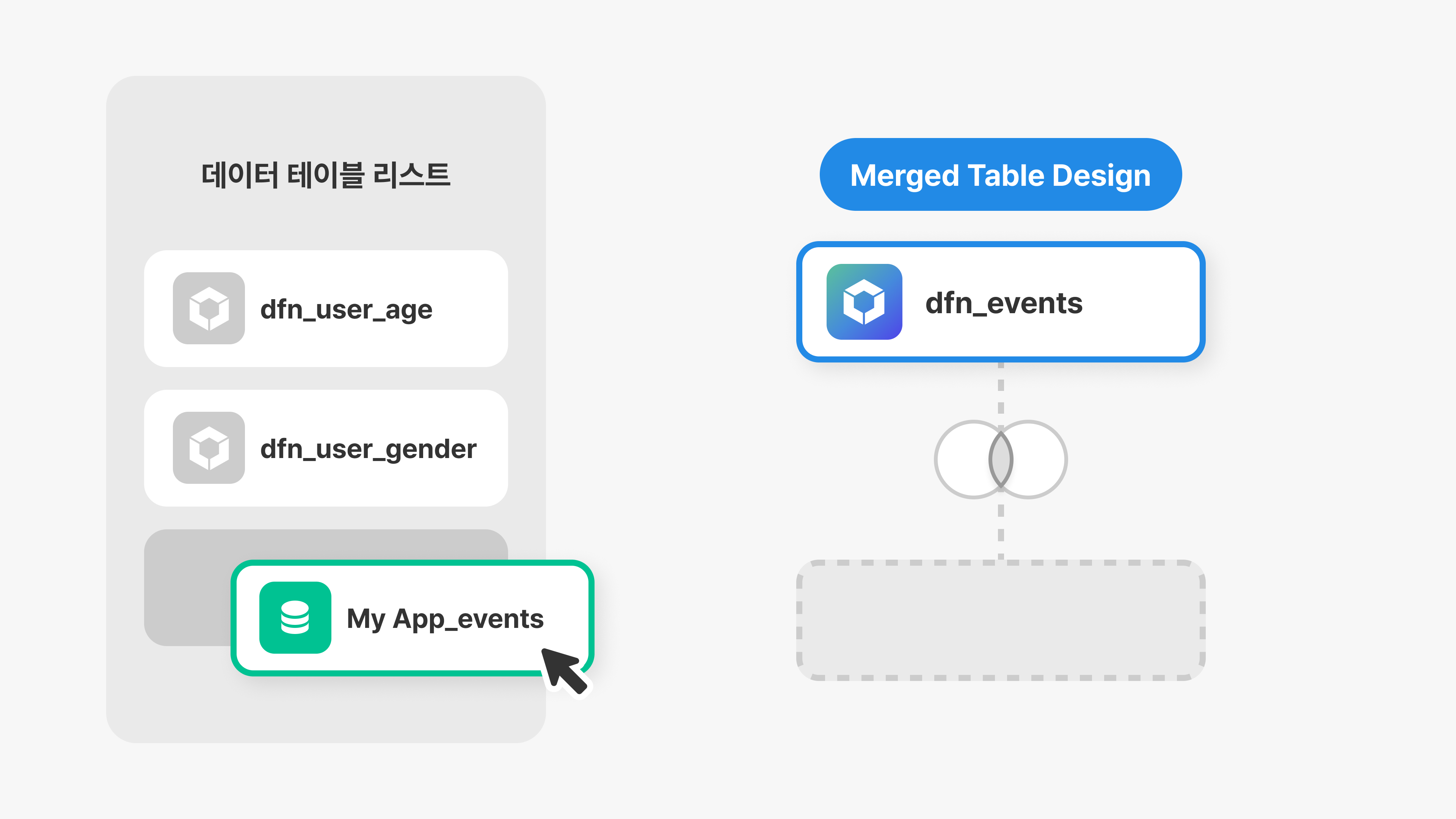
Merged Table
업로드된 데이터는 Merged Table 기능을 통해 병합할 수 있습니다.
테이블 병합은 아래와 같이 진행합니다.
1. 생성된 Event Log 혹은 Meta Table을 드래그하여 Merged Table Design에 추가합니다.
2. 아래 스크린샷과 같이 중간에 ❗(느낌표 아이콘)을 클릭합니다.
3. 병합할 기준을 설정합니다.
Join Type은 다음과 같습니다.
- Left Outer
왼쪽에 설정된 테이블의 것은 조건에 부합하지 않더라도 모두 병합니다. - Full Outer
조건과 관계없이 왼쪽 / 오른쪽에 설정된 모든 테이블 데이터를 병합합니다. - Inner
왼쪽 / 오른쪽 테이블에 공통된 데이터만 결합합니다.
4. 병합 후 테이블 미리보기를 통해 결과를 확인합니다.
데이터 사용법
Data House를 통해 업로드된 데이터는 Analytics에서 별도의 리포트로 확인할 수 있습니다.